

(注:此文章为本人所参与的某学生团队培训大一新生时所用,面向零基础同学,因此没有提及较进阶的内容,以及内容可能不是那么专业。)
第一章 Python语言编程基础
在前面的C语言学习中,我们已经了解了编程的一些基本知识,如位运算、函数等。C语言所培养的逻辑思维和问题解决能力,使我们在学习Python时能够更加高效和自信。
在开发中,Python的强大之处就在于丰富的第三方库,这些库极大地扩展了语言的功能和应用范围。例如,NumPy和Pandas为数据处理和分析提供了强大的工具,PyTorch则支持机器学习和深度学习的开发。Flask和Django则可以让新手很快写出Web页面。这些库不仅简化了复杂任务的实现,还通过高效的预构建功能,帮助开发者节省时间和精力。借助这些资源,开发者可以快速构建和原型化项目,从而加速开发进程,并专注于业务逻辑而非底层实现。这种生态系统的丰富性使得Python在数据科学、人工智能和Web开发等领域成为首选语言。
1.1 Python的安装
Python的安装非常简单,你可以直接在官网上下载最新版本的安装包,点击运行安装即可。
安装之后开始菜单会多出3个图标,从上到下分别是IDLE(Python提供的一个小型IDE)、一些库函数文档和Python终端。
与C语言不同的是,Python是解释性语言,没有编译链接的过程。这意味着其代码在运行时由解释器逐行翻译和执行,而不是在编译阶段生成机器代码。这种特性使得Python具有较高的灵活性和可移植性,开发者可以直接在交互式环境中测试和调试代码。
1.2 Python用作计算器
你可以在Python终端中输入一些简单的代码,来执行一些简单的操作。如基本的加减乘除甚至是位运算。
Python终端中,每输入一句语句之后按回车即可执行语句,对于复合语句则需要输入多行语句。
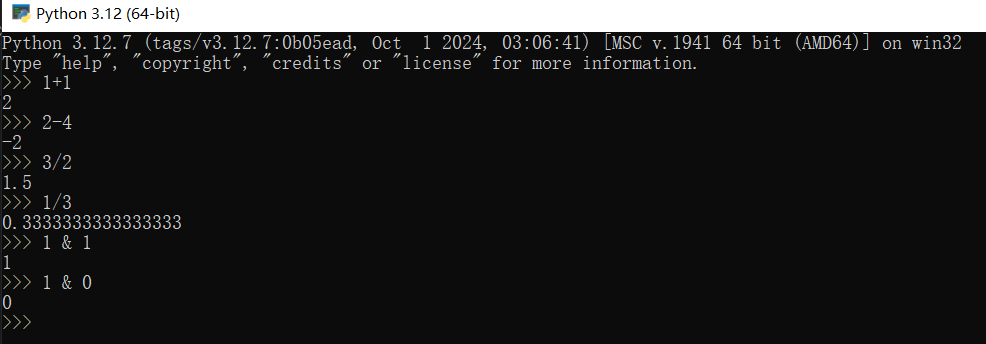
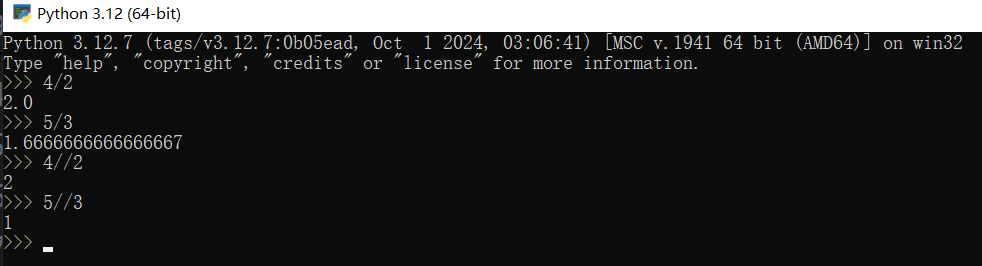
注意,与C语言不同的是,Python中除号返回的结果总是浮点数。即使像4/2这种能整除的,最后也会返回2.0。在Python中想要C语言那样的整除运算需要用“//”(对,就是C语言的注释符号)
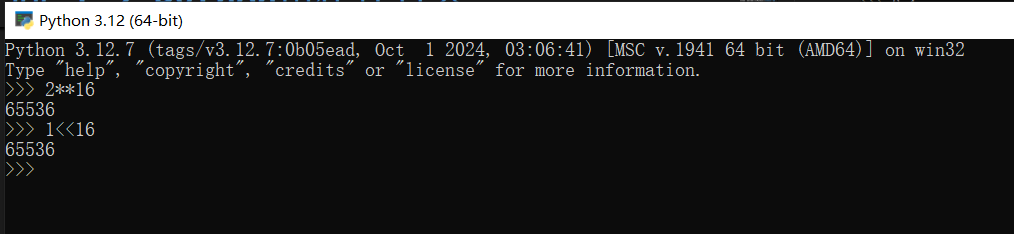
另外,Python可以用双乘号计算次方,如2**16所代表的就是2的16次方。
1.3 Python中的变量以及数据类型
C语言是静态类型语言,每个变量的数据类型在编译时确定,不能改变;而Python是动态类型语言,每个变量的数据类型在运行时确定,可以通过赋值语句改变。
因此Python中定义变量时,不需要指出变量的类型,只需要一句赋值语句即可。当变量被赋值什么数据类型,这个变量在此时就是什么数据类型,就可以执行相应的操作。
我们可以使用type函数来检测变量的类型,这常用于函数中对形参类型的检测。
在使用变量时我们需要检查类型,以及注意在使用前这个变量被定义过。当然,非必要的时候不要去改变一个变量的数据类型。
Python中的数据类型主要包括数字类型(整数int、浮点数float和复数complex),字符串类型 (str),布尔值 (bool),以及序列类型(包括列表list、元组tuple和范围range)。此外,还有集合类型(如集合set)、映射类型(字典dict),以及表示空值的 NoneType。
Python中的整数没有范围限制,Python的int类型可以根据需要动态扩展。当整数的值超出当前内存的限制时,Python会自动分配更多内存来存储更大的数值。
Python中用单引号或者双引号的都是字符串,‘abc’和”abc”完全等效,此外还有三个引号开头的字符串,这种字符串可以多行存储,注意的是,它会存储每一行的换行符。
1 | a = """ |
输出True。
Python中bool值为True和False,注意首字母要大写。此外还有一个特殊的值None,代表空值,逻辑上也为假。
其他的数据类型将在后面详细说明。
1.3.1 Python中变量存储原理
本节内容将在函数章节介绍。
1.4 Python的注释
在Python中,我们使用单行井字号(#)来代表单行注释,使用三个引号开头的字符串代表多行注释。
(#)开头的单行注释会被解释器忽略掉,而三引号开头的多行注释放在函数或者类内部最开始的部分将会被当做函数或者类的简要说明。
1 | # 这是单行注释 |
1.5 第一个Python程序
在刚才的学习中,我们都是在用解释器终端输入语句执行简单任务,然而程序的代码数量十分巨大,我们需要将代码保存到文件中使用。
在Python控制台中,你可以直接输入变量名+回车获取变量的值,但在py代码文件中你需要使用print()函数获取所需要的内容。本教程中,语句前面带有“>>>”说明本例子在控制台运行,不带这个符号的例子是在代码文件中编写的。
Python官方给我们提供了一个简单的IDE,我们打开IDLE,点击File->New File
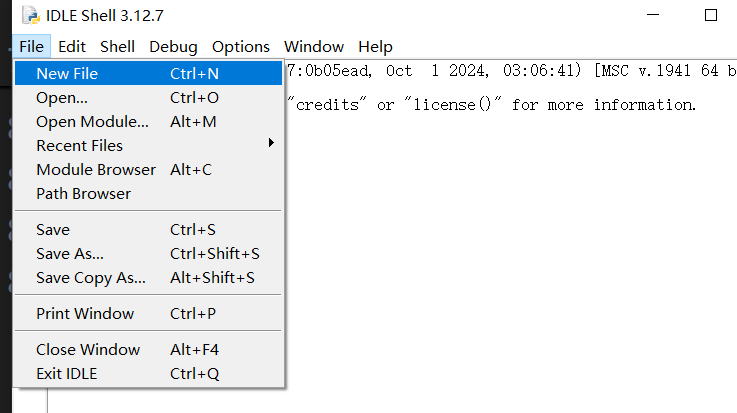
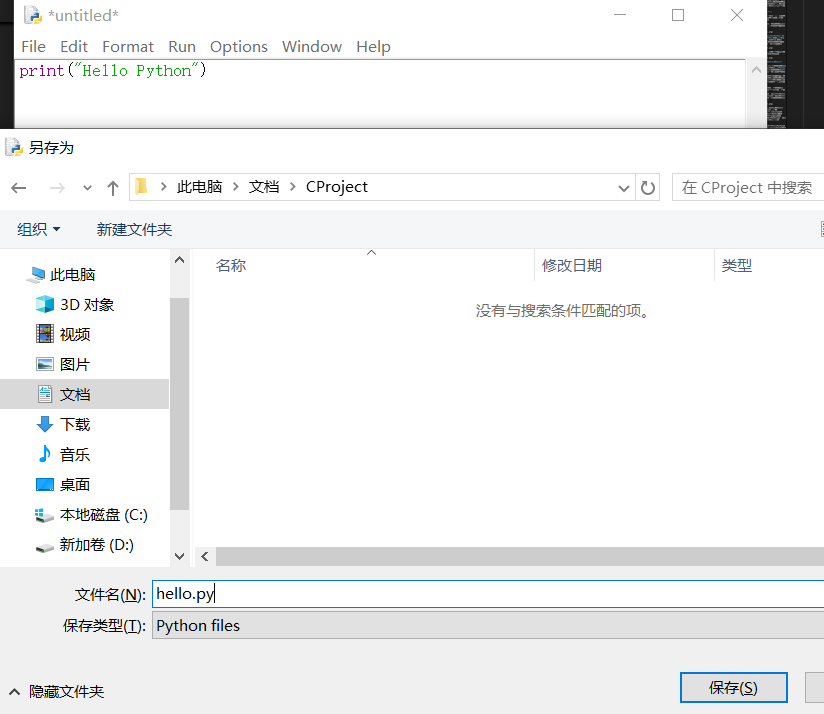
输入代码后点击保存,选择保存位置
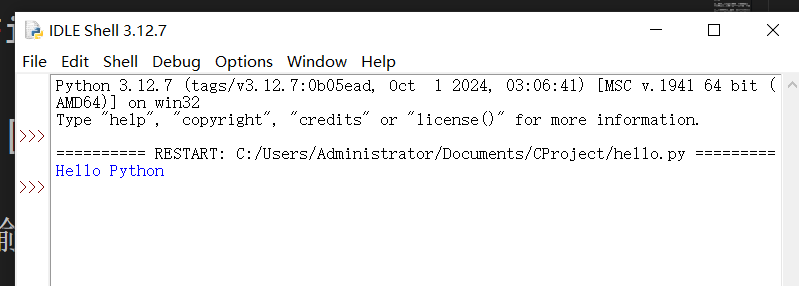
之后我们就可以点击Run或者F5运行我们的代码
另外我们也可以在Windows终端(cmd或者PowerShell)中切换到py文件目录,用解释器跑我们的代码。
1 | python hello.py |
1.6 PyCharm的安装
虽然IDLE具备基本的IDE功能,很多教程也是建议新手使用这个学习。但是它并没有代码补全功能,界面也十分简陋。我推荐直接使用PyCharm来学习Python,因为反正项目开发的时候也要用PyCharm。
直接在官网下载PyCharm Community版,社区版是免费使用的。
建议将这些全部勾选。
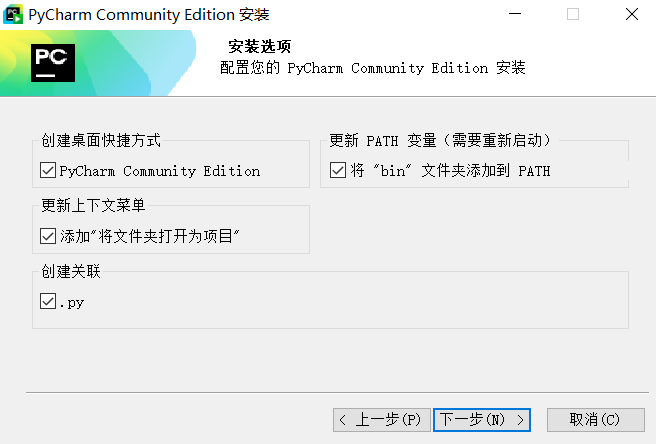
进入PyCharm后我们点击新建项目,选择一个路径即可。
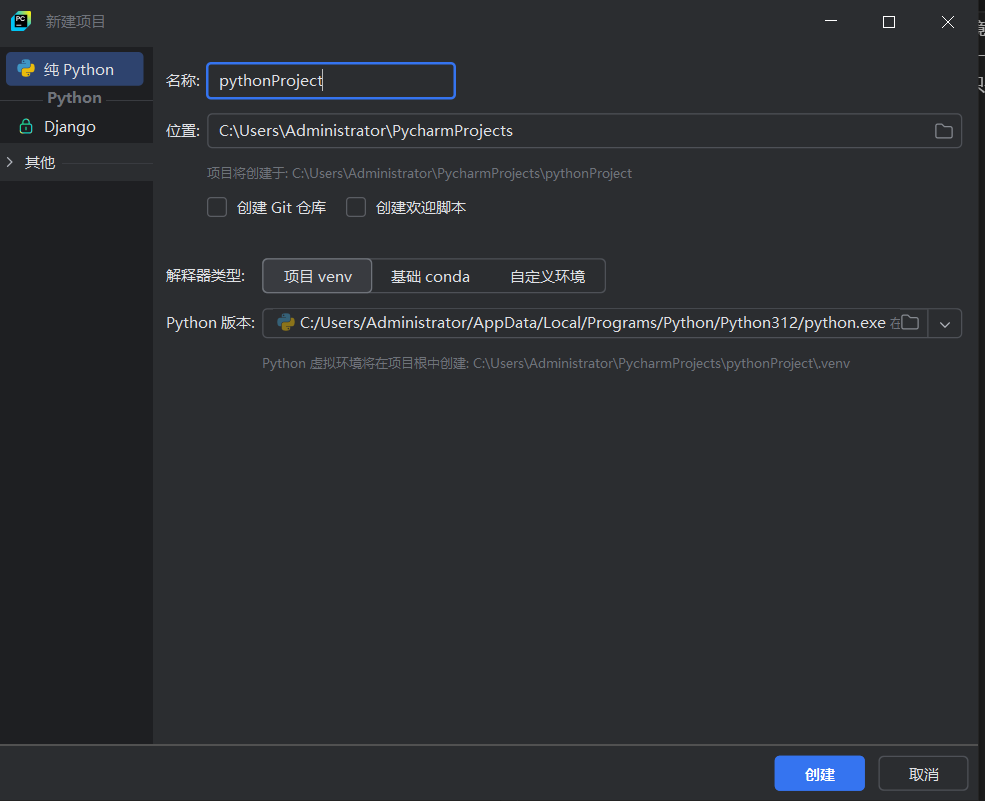
PyCharm会对每一个Python项目生成独立的虚拟环境,主要是为了实现依赖隔离,避免不同项目之间的库和依赖冲突。这样可以确保每个项目在干净且一致的环境中运行,从而减少环境差异导致的问题。同时,这种方法提升了项目的可迁移性,因为只需复制项目文件及其虚拟环境即可确保所需依赖一同带走。
之后我们在项目名称这里右键点击新建Python文件。
如果说需要调节字体的话点击文件->设置
选择编辑器->字体,改变字号即可。
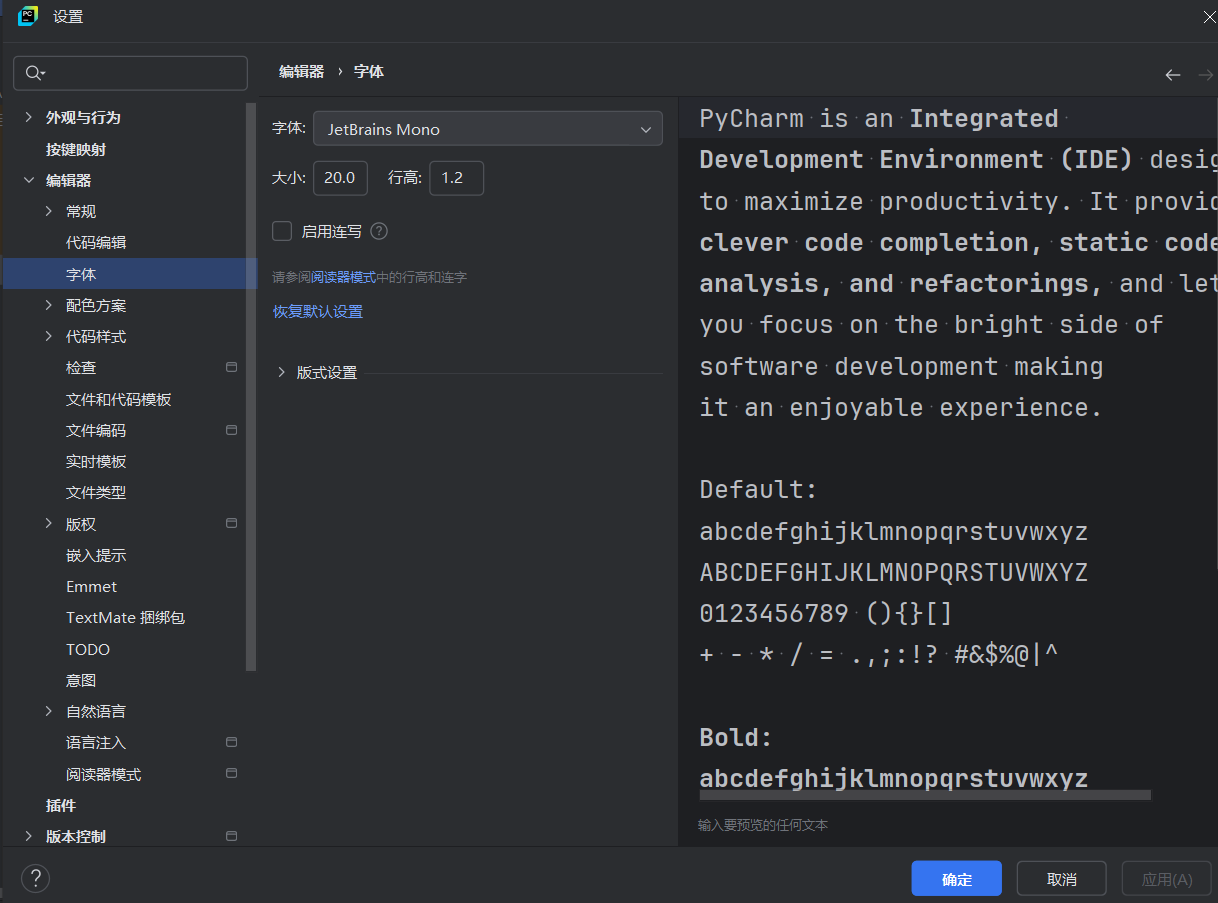
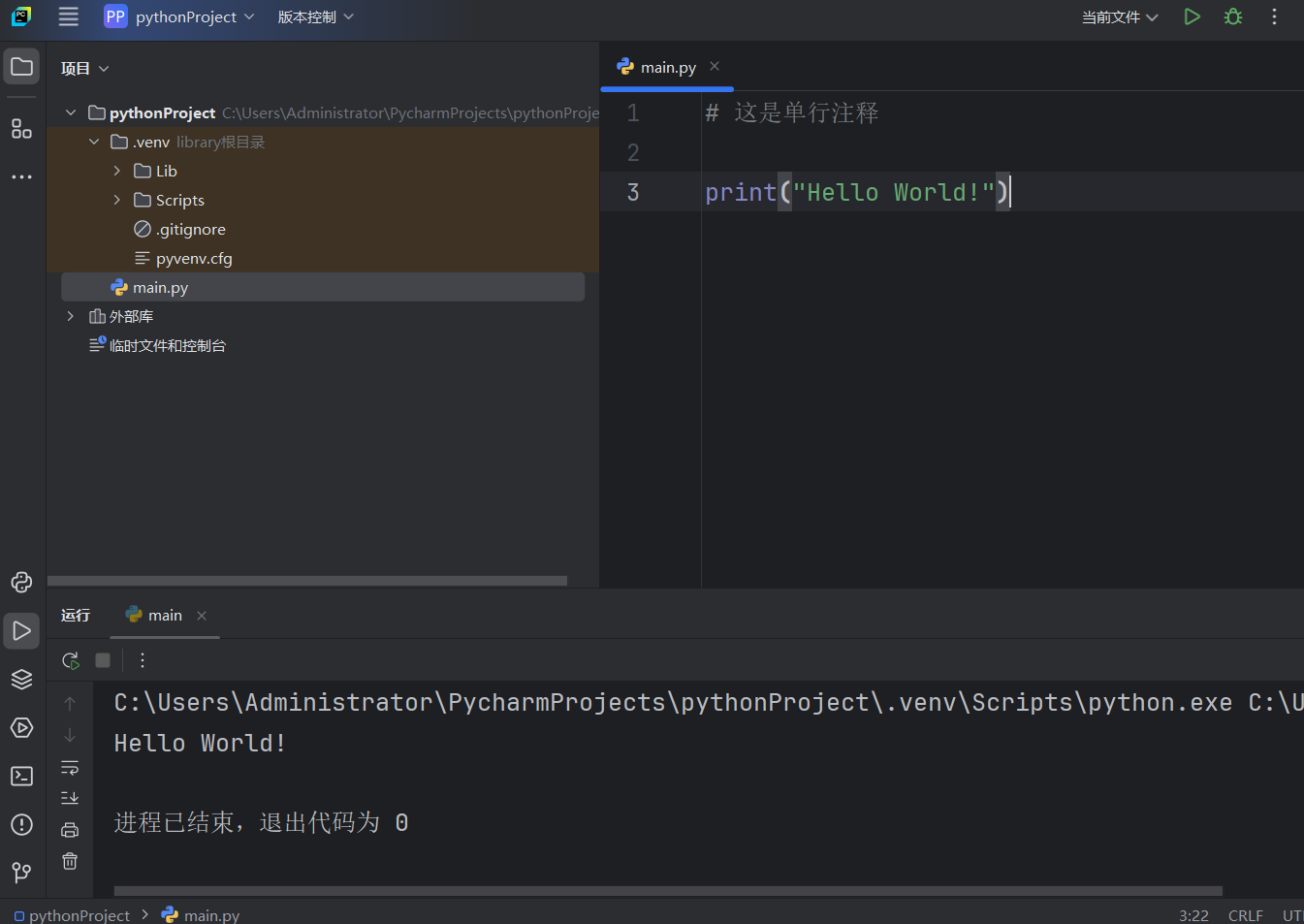
写完代码后点击右上角的Run即可。
第二章 字符串、列表、输入输出函数、基本控制语句
为了介绍Python的流程语句,本章先简单介绍Python的字符串和列表的基本操作。在后面的章节我们再详细介绍这两种数据类型的进阶操作。
2.1 字符串
在Python中,无论用单引号还是双引号包裹起来的一个或多个字符,都是字符串。
与C语言不同的是,Python的字符串具有许多灵活的操作,比如拼接、比较等。字符串中的“\”代表转义,与C语言的转义字符相同。
2.1.1 字符串的拼接
在Python中,可以使用加号来对两个字符串进行拼接,比如:
1 | s = "abc" |
此外,字符串可以用乘号以及某个数字(*x)表示将字符串重复多次,比如:
1 | s = "a" |
当然,这两种方式可以复合使用:
1 | s = "ab" |
需要注意的是,字符串拼接的时候,要求两个拼接元素都是字符串。如果需要将其他类型的元素转化为字符串,需要使用str()函数。
1 | n = 100 |
在Python中,几乎所有类型的变量都可以用str函数转化为字符串,因为很多类都有或者重载了__str__()方法。
2.1.2 字符串的比较
在Python中,字符串的比较可以用双等号、大于号、小于号、大于等于号、小于等于号、不等于号来进行比较。不过最常用的还是双等号和不等号。
1 | s = "abc" |
2.1.3 字符串的索引和切片
可以使用len()函数获取某个字符串的长度
1 | len("abcdef") |
字符串支持索引(下标访问),第一个字符的索引是0。最后一个字符下标为 len(str) - 1。
1 | s = "Python" |
在使用索引时,注意不要超过索引范围,否则就会报错:
1 | s = "Python" |
此外,索引还支持负数,从-1开始计数。用负数索引时,从右边开始计数,右面第一个元素为-1,左面第一个元素则为-len(str)。
1 | s = "Python" |
Python的字符串还支持切片,即获取子字符串。格式为:
1 | [a:b] # 从索引a(包含)到索引b(不包含)的字符组成的子串 |
1 | s = "Python" |
如果冒号前的数字省略则默认为0,如果冒号后的数字省略则默认为len(str)
1 | s = "Python" |
切片的索引也可以用负数,但是切片的方向不会发生改变(负数索引仅代表位置)。
1 | s = "Python" |
Python的字符串不可以通过索引进行修改,因为索引返回的只是长度为1的字符串。
1 | s = "Python" |
但是可以通过切片+拼接的方式实现字符串的修改:
1 | s = "Python" |
2.1.4 字符串的格式化
在Python中,字符串可以这样插入其他变量:
1 | n = 10 |
在字符串的引号前面加上小写字母f,代表这个字符串需要格式化,之后在字符串内部可以用花扩号加上变量名代表要插入的数据。如果字符串前不加小写字母f,则会忽略花扩号:
1 | n = 10 |
2.2 列表
Python的列表可以存放多个数据,用方括号(中括号)包裹,用逗号将每个元素分隔开。列表中的元素数据类型可以不同,但习惯上我们将相同的数据类型放在一个列表中。
可以用list()创建一个空表,也可以直接用方括号加元素创建列表。
1 | l = list() # 创建空列表 |
和字符串一样,列表也支持索引和切片:
1 | l = [1,2,3,4] |
列表也支持使用加号合并:
1 | l = [1,2,3,4] |
与字符串不同的是,列表可以通过索引修改某个位置的元素的值:
1 | l = [0,2,3,4] |
Python中的简单赋值绝不会复制数据。当你将一个列表赋值给一个变量时,该变量将引用现有的列表。因此在传值整个列表的时候一定要注意这个问题。
1 | l1 = [1,2,3,4] |
如何解决这个问题,我们将在函数章节说明。
len()函数可以返回列表中元素的个数:
1 | l = [1,2,3,4] |
列表的元素可以是任意的数据类型,当然也包含列表类型,构成嵌套列表:
1 | l = [[1,2,3,4], ['a','b','c'], 12.34] |
可以用关键字in判断某一个元素是否在列表中:
1 | l = [1,2,3,4] |
2.3 输入输出函数
在Python中,可以使用print()函数输出字符串,print默认带一个换行,函数的形参可以不是字符串,只要它可以转化为字符串。
1 | print("Hello!") |
print()函数除了接受一个字符串外,还可以给它的形参end传递一个字符串,代表输出结束后再输出end字符串作为末尾标志。这个形参默认为’\n’。
1 | print("Hello", end="123") |
在Python中,使用input()函数从控制台读取一行数字,遇到换行才结束。input()函数返回的是一个字符串,需要使用int()或float()函数将字符串手动转化为整数或者浮点数。
1 | x = input() # 下面一行是键盘的输入 |
1 | x = input() |
input()函数可以传入一个字符串,此时input()函数将先输出传入的字符串,再等待输入。
1 | n = input("Please enter n:") |
2.4 基本控制语句
本节将简单介绍Python中的流程控制语句——条件语句与循环语句。
2.4.1 Python使用缩进定义代码块的范围
C/C++、Java等其他语言,使用花扩号来定义代码块的范围。然而Python是特殊的,Python使用缩进定义代码块的范围。缩进在 Python 中起着至关重要的作用,因为它决定了代码的逻辑结构。
在Python代码文件中,通常用4个空格或者一个制表符(按TAB键)作为一个缩进单位。同一个代码文件必须使用相同的缩进单位。
每条语句属于哪部分完全是靠缩进区分的,因此不能像C语言那样压行写代码。正确的缩进不仅可以避免语法错误,还可以提高代码的可读性。
举个例子:
1 | for i in range(100): |
2.4.2 Python中的真值和假值
在Python中,None、False、0、空字符串、空列表、空元组、空字典和空集合为假值,其他的为真值。
2.4.3 pass、and、or、not关键字
在Python中,pass是一个空语句的占位关键字,代码执行到此处什么都不执行,常用于语法上需要语句但程序不需要执行任何操作。Python的函数定义、类定义、条件语句和循环语句语法上都需要语句,如果你不想执行任何操作,那么就可以用pass语句占位。
在Python中,表示多个条件的复合关系需要用到与(and)、或(or)、非(not)关键字。这些关键字用于条件连接,并不是位运算。运算结果与C语言的(&& || !)一样。
| cond1 | cond2 | cond1 and cond2 |
|---|---|---|
| False | False | False |
| False | True | False |
| True | False | False |
| True | True | True |
| cond1 | cond2 | cond1 or cond2 |
|---|---|---|
| False | False | False |
| False | True | True |
| True | False | True |
| True | True | True |
| cond1 | not cond1 |
|---|---|
| False | True |
| True | False |
2.4.4 if条件语句
条件语句由if——elif——else组成,基本格式为:
1 | if condition1: |
例如,用户输入成绩,根据成绩进行分级:
1 | # 从用户输入成绩 |
1 | Please enter your score: 59 |
同样的,Python也支持条件嵌套,但一定要注意缩进值。
还是举这个例子:某动物园购票,分学生票、老年票、儿童票和成人票。如果顾客能够拿出老年证或者学生证,就可以购买相应的票。如果没有相关证件,则根据年龄进行判断。
1 | # 提示用户输入年龄 |
2.4.5 while循环语句
while循环语句的结构为:
1 | while cond: |
例如,计算1+2+3+…+n的和:
1 | # 初始化总和和当前数字 |
2.4.6 for迭代语句
Python的for语句与C语言不同,Python的for循环语句用来枚举列表、字符串等一些有序序列的元素,用法为:
1 | for 元素 in 可迭代序列: |
比如,枚举某个列表存放的字符串,并输出它以及长度:
1 | lang = ["CPP", "Python", "Java", "Assembly", "C"] |
输出为:
1 | CPP 3 |
也可以用来枚举字符串中的每个字符:
1 | s = "Hello World!" |
1 | index of 0 is: H |
2.4.7 range()函数
内置函数range()用于生成等差数列:
1 | for i in range(5): |
1 | 0 |
生成的序列不包含终点。
range函数可以传一个数字、两个数字或者三个数字。(原理:函数形参的默认值)
当range只接受一个参数n时,代表生成0n-1的序列,当接受两个参数a与b时,生成ab-1的序列,当接受第三个参数c时,代表生成的序列每两项的差值为c:
1 | print("range(5)") |
1 | range(5) |
2.4.8 break和continue语句
与其他编程语言一样,break代表直接中止循环,continue代表继续下一轮的循环。
在循环体执行过程中,如果遇到了break语句,那么就中断当前的循环并跳出循环体。如果break出现在嵌套循环中,只会退出当前所在的循环层级。
例如,下面是一个简单的程序,让用户猜测预设的数字,程序会提示用户猜测的数字是“太大”还是“太小”,直到用户猜对为止。(这个在C语言教程中提到过)
1 | # 预设的数字 |
1 | Guess the number (between 1 and 100): |
continue语句用于跳过当前循环中的剩余部分,并直接进入下一次迭代。它常用于控制循环的执行流程,跳过不需要处理的特定条件。
例如,打印一个列表中的所有偶数:
1 | numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] |
1 | Even numbers in the list: |
2.4.9 循环的else子句
在for或while循环中可能对应一个else子句。如果循环在未执行break的情况下结束,将会执行else子句的内容。
1 | while cond: |
比如说,寻找2到10以内的质数:
1 | for n in range(2, 10): |
1 | 2 is a prime number |
第三章 函数和模块
3.1 Python中变量的存储方式
在高级语言中,变量是内存数据以及其地址的代表。C语言中,我们的变量可以直接存储数据,并且每个变量都有其唯一的地址,称之为指针。C语言这样直接把变量的数据存储在变量区的方式叫做值语义。在C语言中,哪怕是指针变量,也是直接存储的值。(指针变量存储的就是一个地址信息)
而在Python中,变量的存储方式是通过对象引用来实现的。这种存储方式叫引用语义。
在理解Python的变量存储方式前,需要了解两个事实:
- 一切都是对象:在Python中,所有的数据类型(包括基本数据类型如整数、浮点数、字符串等)都是对象。每个对象都有一个类型和一个值。
- 对象引用:变量实际上是对对象的引用,而不是直接存储数据值。赋值操作只是在变量与对象之间建立了一个引用关系。
以基本数据类型举例(不可改变的对象)
不可改变的对象,如整数、浮点数、字符串和元组。当这些对象的值被改变时,实际上是创建了一个新的对象,原来的对象不受影响。
不可改变的对象传递给变量的时候,你可以简单的认为他是值传递的,跟C语言值语义变量在效果上是一样的。
当你给一个变量赋值时,比如 a = 10,Python会创建一个整数对象10,然后让变量a指向这个对象。
如果你再做b = a,此时b也会引用同一个对象(即整数10),而不是创建一个新的对象。
1 | # 不可变对象 |
以列表举例(可以改变的对象)
可以改变的对象,如列表、字典和集合。当这些对象的内容改变时,原对象仍然存在,内容被修改的是同一个对象。因此在传递引用给函数形参的时候就会出现问题:
1 | # 可变对象 |
1 | def add(l, x): |
简要概括
你如果没法消化吸收刚才的内容,可以暂时不去应扣。你暂时只需要知道:
- 复制列表、字典的时候用切片来复制(如果列表里还嵌套列表的话这样也不行……)
- 给函数形参传递列表、字典的时候需要慎重考虑一下
- 干脆不写需要传递列表、字典的函数,完全可以使用元组代替。
3.2 函数
3.2.1 函数的定义
在Python中,函数的定义形如:
1 | def 函数名(形参列表): |
由关键字def开头,后接函数名称,括号内为形参列表。
函数内部的第一行通常为三引号的注释,代表函数的文档。通常函数的编写者要在此处简单介绍函数,如函数的功能、形参、以及返回值类型。
例如,下面用定义了一个Fibonacci数列的函数
1 | def Fibo(n): |
3.2.2 函数的返回值
函数的返回值类型由函数内部的return语句决定,换句话说,函数内部可以返回任何类型的数据,函数的编写者需要在注释里明确说明返回值的类型。如果函数没有返回值,则函数的返回值为None。
比如下面的函数,如果a不是int,则返回None,否则返回布尔值、字符串或者整数。
1 | def fun(a): |
3.2.3 函数的形参
在Python中定义函数的时候,函数的形参在函数名后面用括号定义,每个形参之间使用逗号分开:
1 | def f1(a, b, c): |
上面定义的两个函数,f1需要给出三个形参的值,f2需要给出两个形参的值。
3.2.3.1 形参的默认值
Python的函数可以为参数指定默认值。这是一个非常有用的方式。调用函数时,可以使用比定义时更少的参数,例如:
1 | def ask_ok(prompt, retries=4, reminder='Please try again!'): |
该函数可以用以下方式调用:
- 只给出必选实参:
ask_ok('Do you really want to quit?') - 给出一个可选实参:
ask_ok('OK to overwrite the file?', 2) - 给出所有实参:
ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!')
需要注意的是,默认值只在定义函数的时候计算出来,所以:
1 | i = 5 |
仍然输出为5。
重要警告: 默认值只计算一次。默认值为列表、字典或类实例等可变对象时,会产生与该规则不同的结果。例如,下面的函数会累积后续调用时传递的参数:
1 | def f(a, L=[]): |
输出结果为:
1 | [1] |
原因:默认值存储的是这个列表的引用。
不想在后续调用之间共享默认值时,应以如下方式编写函数:
1 | def f(a, L=None): |
3.2.3.2 通过形参名传递参数
在Python中,可以使用 形参名=值 的形式调用函数,指定给一个形参传递值。
使用 形参名=值 的形式称为关键字参数,只使用值的参数称为位置参数。
假设定义了以下函数:
1 | def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'): |
该函数接受一个必选参数(voltage)和三个可选参数(state, action 和 type)。该函数可用下列方式调用:
1 | parrot(1000) # 1 个位置参数 |
以下的调用都是不符合语法的:
1 | parrot() # 缺失必需的参数 |
函数调用时,关键字参数必须跟在位置参数后面。所有传递的关键字参数都必须匹配一个函数接受的参数(比如,actor 不是函数 parrot 的有效参数),关键字参数的顺序并不重要。
3.3 模块
Python中, import 关键字用于导入其他模块的函数、变量、类等资源。
Python把一些常用的函数定义存入不同的文件,供其他代码使用。这个文件就是模块。使用模块有一个好处,不同程序调用同一个函数时,不用把函数定义复制到各个程序。
同时你也可以导入自己的py脚本当作自定义的模块。
3.3.1 使用import导入Python内置模块
Python内置了许多模块,比如os模块、math模块、random模块、socket模块等等……因此在写Python项目的时候,你可以先去互联网查一查,有没有相关功能的模块。
在本教程中举几个常用的例子,比如说os模块:
1 | import os |
请注意,在使用模块里的函数时,你需要加上模块的名字,然后加上点引出模块内部的函数。
这样的做法有一点好处就是,可以防止模块的函数与你代码自定义的函数发生冲突。
Python中常用的模块还有:
1 | import math |
1 | import random |
1 | import datetime |
3.3.2 使用from … import导入模块的部分内容
如果你觉得模块名过于长,你可以使用 from ... import ... 导入模块的部分内容。
比如:
1 | from math import comb, sqrt, sin, cos, pi |
1 | from random import randint |
1 | from datetime import datetime |
需要注意的是,使用from导入模块的内容,可能会覆盖模块内原有的重名定义,也有可能原有的重名定义覆盖到你的导入。
3.3.3 给导入模块起别名
如果模块名本身就被使用了,或者使用from导入时,模块的某个函数会和已定义的函数重名,你可以用 as 给模块起一个别名:
1 | from random import randint as rdi |
1 | import datetime as dt |
3.3.4 使用pip安装第三方模块
Python的强大就在于其具有丰富的第三方模块,但这些模块都不是自带的,python可以使用pip安装指定的模块
打开Windows终端,输入 pip install 包名 就可以安装你想要去安装的第三方模块,以flask模块举例:
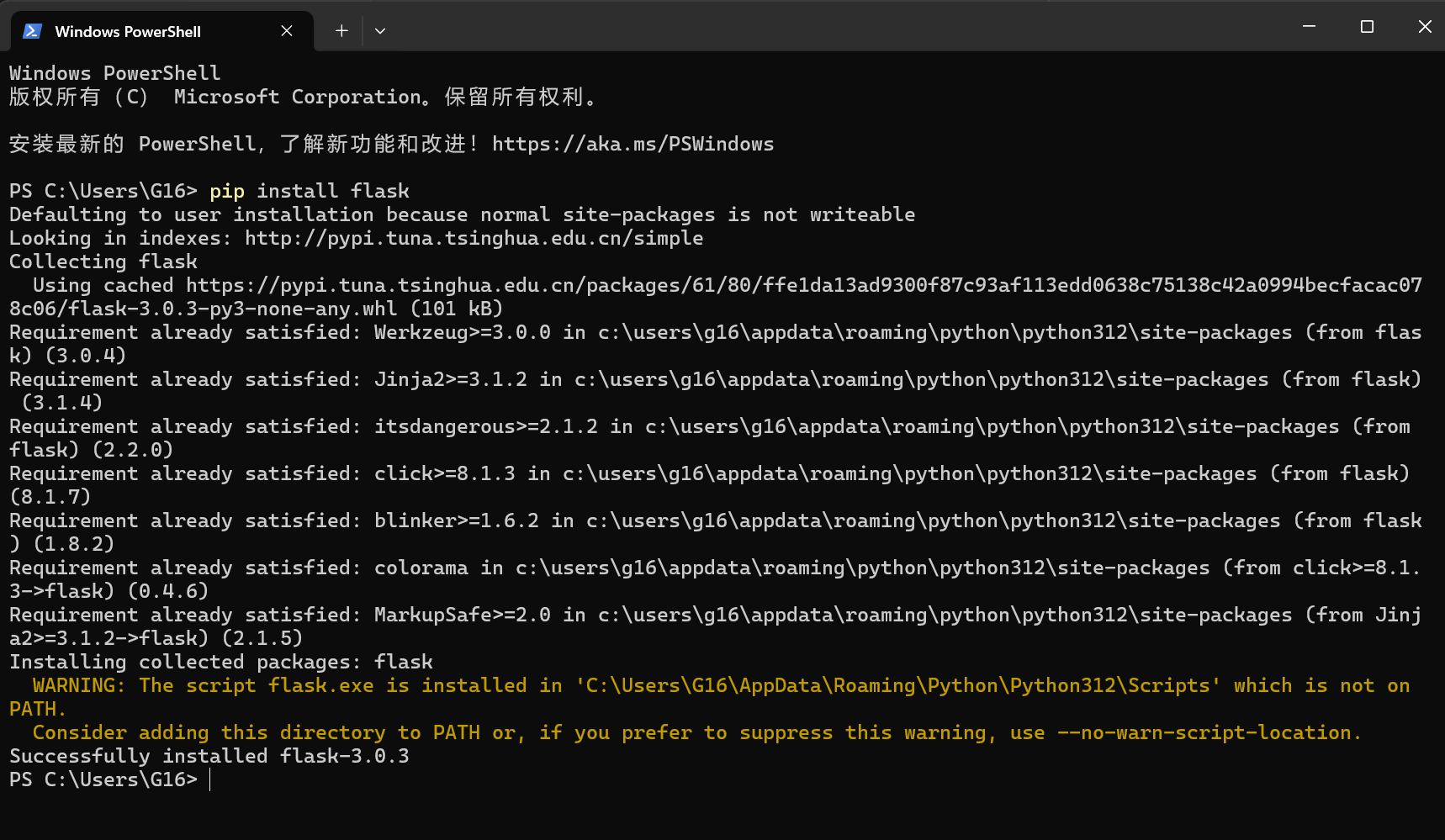
这样你的Python就安装了flask模块,可以使用flask框架的一些东西了。
对于Pycharm来说,它会给每一个项目都生成一个小型Python运行环境(因为有些项目需要使用某个模块的旧版本,而另一些项目需要同样模块的新版本),因此你需要单独的给每一个项目的虚拟环境安装模块。
点击右下角的“Python 3.x”的按钮,它会弹出一系列项目的环境:
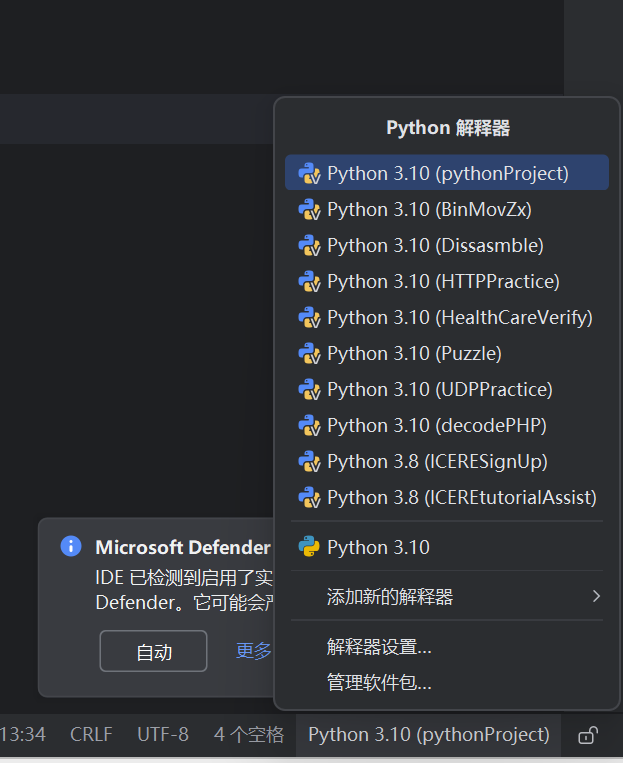
选择你当前打开的项目,点击“解释器设置”。
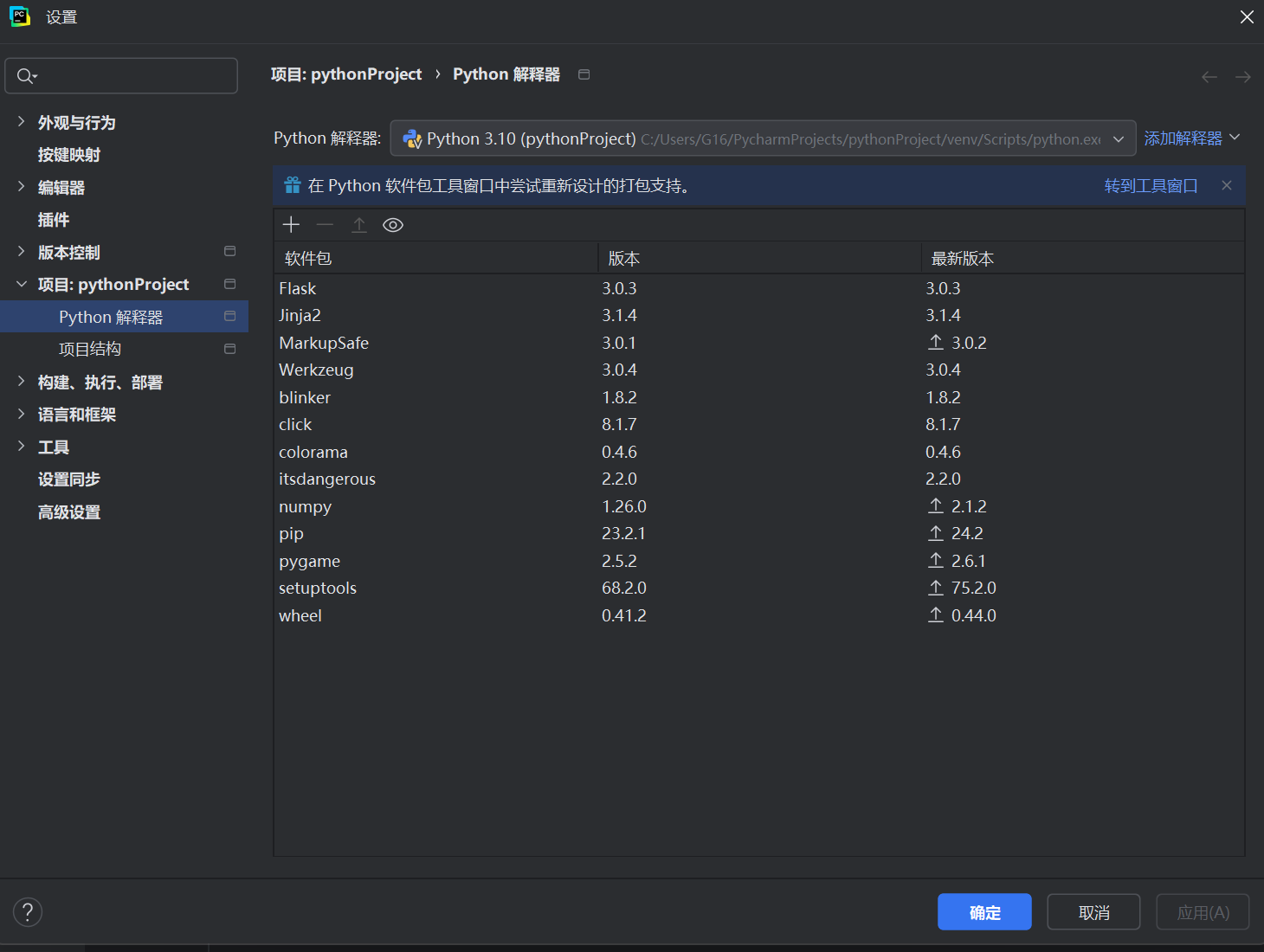
在项目,这个选项有一个Python解释器,这里会列出你当前项目的Python环境安装了什么模块,你可以点击右侧左上角的加号,添加你想要安装的包。
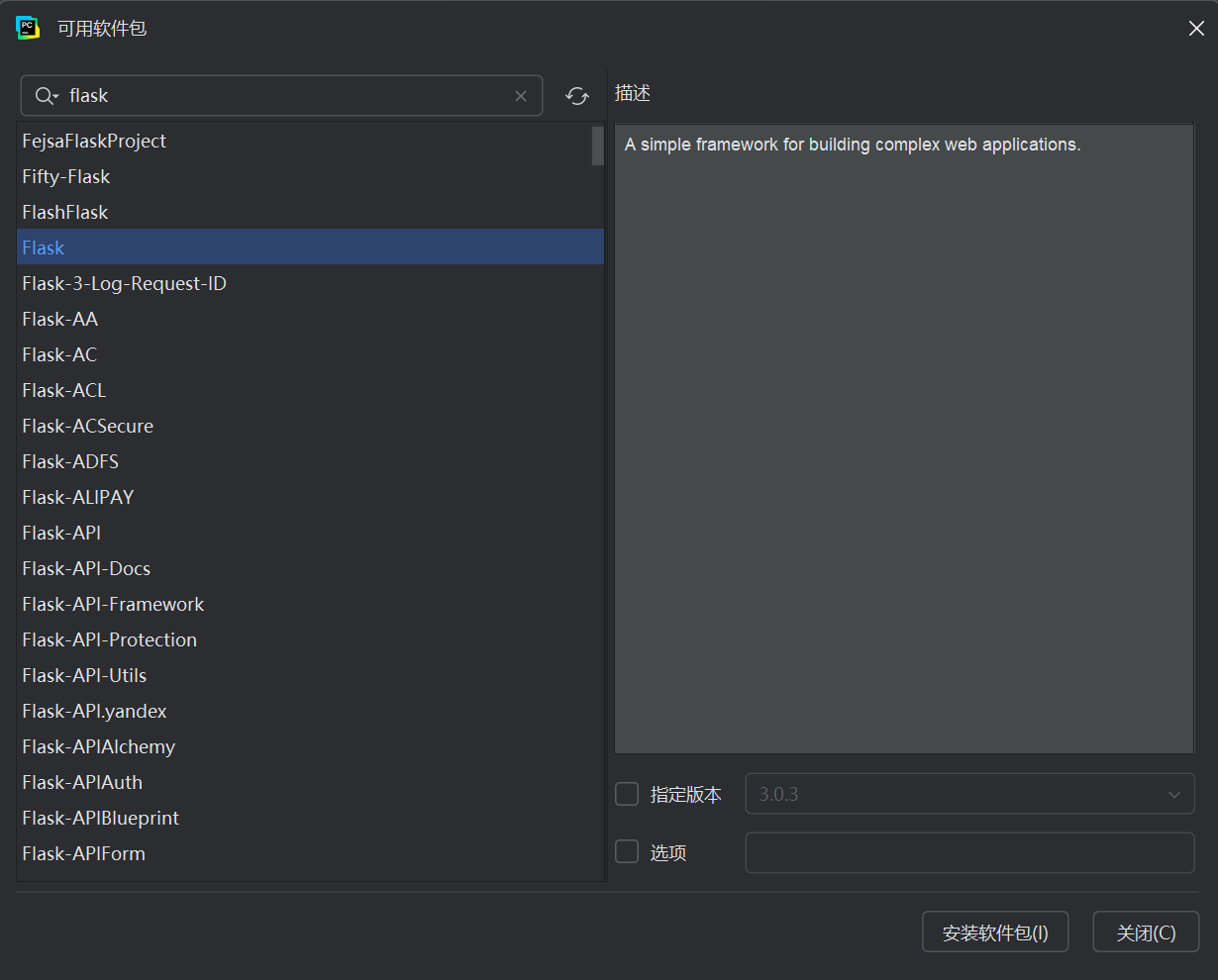
然后输入名字,选择你需要安装的模块,安装就可以了。
题外话 这么多知识记不住怎么办?
本来想在第一次培训课上就说这个事情的,但总是忘掉,于是暂时写在教程上吧。
对于新手来说,突然高强度接受这么多知识肯定是受不了的。(Python官方文档比我写的还长,讲了很多更抽象的用法,有一堆冷门的我也记不住……)
你需要做的是只需要了解基本语法就可以了,模块以及模块的函数完全可以在需要用的时候现去上互联网进行搜索,甚至现在还可以像AI提问。
之后我们培训的框架开发更是如此,一个框架会有许多许多的模块以及函数,刚去学习根本记不住几个(甚至用了好长时间也不会记住一个框架的所有内容),这个时候学会在需要用的时候上网搜索即可。
在学习一个技术的时候,不断的查看文档或者去提问是一个非常有效的方式。项目开发并不是期末考试,不会要求你写的所有代码都是在你脑子里的。对于初学者来说,能会去使用框架就可以了。
第四章 列表、集合、字典
本章将重点讲一下Python中常用的四个数据类型。
4.1 列表
4.1.1 列表类的方法
列表的常用方法如下(其中list为一个列表对象):
1 | list.append(x) |
这些方法的简单使用:
1 | fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana'] |
注意insert, remove或sort等仅修改列表的方法都不会打印返回值,它们返回默认值None。
4.1.2 列表推导式
列表推导式创建列表的方式更简洁。常见的用法为,对序列或可迭代对象中的每个元素应用某种操作,用生成的结果创建新的列表。
例如,创建平方值的列表,我们用之前学过的方法为:
1 | squares = [] |
但是你可以写成这样:
1 | squares = [x**2 for x in range(10)] |
列表推导式的方括号内包含以下内容:一个表达式,后面为一个 for 子句,然后,是零个或多个 for 或 if 子句。结果是由表达式依据 for 和 if 子句求值计算而得出一个新列表。 举例来说,以下列表推导式将两个列表中不相等的元素组合起来:
1 | [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y] |
等价于:
1 | combs = [] |
4.2 元组
列表和字符串有很多共性,例如,索引和切片操作。这两种数据类型是序列。
本节介绍另一种标准序列类型:元组。
元组由多个用逗号隔开的值组成,例如:
1 | t = (12345, 54321, 'hello!') |
元组与列表很像,但使用场景不同,用途也不同。元组的元素是不可变的,通过解包或索引访问。
序列解包的方法如下:
1 | t = (12345, 54321, 'hello!') |
4.3 集合
Python还支持集合这种数据类型。集合是由不重复元素组成的无序容器。基本用法包括成员检测、消除重复元素。集合对象支持合集、交集、差集、对称差分等数学运算。
创建集合用花括号或 set() 函数。注意,创建空集合只能用 set(),不能用 {},{} 创建的是空字典。
1 | basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} |
可以用in关键字快速检验某个元素是否在集合内部:
1 | 'orange' in basket # 快速成员检测 |
集合可以由列表、字符串等序列初始化,此时集合的初始值为序列的每一个元素:
1 | # 演示针对两个单词中独有的字母进行集合运算 |
两个集合直接可以用基本运算符号代表差集(减号)、并集(|,位或号)、交集(&,位与号)、对称差集(^,异或号)
可以简单想一想为什么用这些算术符号定义集合的操作。
1 | a - b # 存在于 a 中但不存在于 b 中的字母 |
4.4 字典
另一个非常有用的Python内置数据类型是字典,它是一种映射关系。
列表和字符串可以通过索引访问元素,而字典是通过键访问元素的。(形象的来说,字典的索引可以是其他的数据类型,但这个数据类型需要是不可以改变的)
举例说明:字符串和数字可以当作键,而列表和集合就不能当作键。对于元组来说,如果元组内部不含可改变类型也可以当作键。
常用的是把字符串当作键值。
字典的存储方式为 键:值,一个键对应一个值。
字典的键必须是唯一的。花括号 {} 用于创建空字典。另一种初始化字典的方式是,在花括号里输入逗号分隔的键值对。
形象的来说,使用字典,你可以给一个字符串赋一个值,来实习字符串到其他数据类型的转换。
1 | tel = {'jack': 4098, 'sape': 4139} # 使用 键:值 的形式初始化字典 |
字典的主要用途是通过关键字存储、提取值。用 del 可以删除键值对。用已存在的键存储值,该键的旧值会被取代。通过不存在的键提取值,则会报错。
1 | tel = {'jack': 4098, 'sape': 4139} |
对字典执行 list(d) 操作,返回该字典中所有键的列表。检查字典里是否存在某个键,可以使用关键字in。
1 | tel = {'jack': 4098, 'sape': 4139} |
dict() 函数可以直接用键值对的列表创建字典:
1 | dict([('sape', 4139), ('guido', 4127), ('jack', 4098)]) |
当你需要同时遍历字典的键与值,可以使用items()方法:
1 | knights = {'gallahad': 'the pure', 'robin': 'the brave'} |
当你想获取字典的值的列表,你可以使用 list(d.values())
1 | tel = {'jack': 4098, 'guido': 4127, 'irv': 4127} |
title: 第五章 类与对象
第五章 类与对象
5.1 面向对象编程的基本概念
5.1.1 类
面向对象编程(Object-Oriented Programming, OOP)是一种程序设计模式,旨在通过将数据和行为封装在对象中,增强代码的模块性、重用性和可维护性。
面向对象编程是相对于面向过程编程来讲的,更贴近事物的自然运行模式。
比如说人类,具有身高、体重、姓名、性别等属性,同时还具备吃饭、呼吸、学习、摆烂等方法。类似的,在编程的时候,将多种具有一定联系的变量和函数封装在一起组成的一个集体,就是——类。
用编程语言实现人类,就是定义一个Person类,具有身高、体重、姓名性别这些变量,以及具有吃饭、呼吸、学习等函数。
通常在OOP中,将类的成员变量称之为类的属性,将类的成员函数称之为类的方法。
5.1.2 对象
对象是OOP的核心概念。它是程序中某一个类的实例。比如上述定义的Person类,小明就可以看作是Person类的一个实例,他具有Person类的所有属性以及方法。
可以简单理解为:对象是类的一个实例,类是对象的模板。
5.1.3 封装、继承、多态、抽象
封装是OOP的基本特性之一,它将数据和操作这些数据的函数封装在一起,隐藏内部实现细节,只暴露必要的接口。封装带来的好处包括信息隐藏和控制访问。通过封装,调用者无需关系类的内部的具体实现,只需要使用类提供的方法即可。
继承是OOP的一种机制,允许一个类(子类)继承另一个类(父类)的属性和方法。继承可以提高代码的重用性和组织性。子类可以重用父类的代码,还可以重写父类的方法以实现特定功能。
多态是指同一操作可以作用于不同类型的对象,表现出不同的行为。这使得程序能够根据对象的实际类型调用相应的方法,增强了灵活性。
抽象是指将复杂的现实世界简化为可管理的模型,强调对象的特性而隐藏不必要的细节。在OOP中,可以使用抽象类和接口来定义基本的结构和行为。
以上的概念将会在代码中进一步说明。
(如果用C++术语来描述的话,类成员(包括数据成员)通常为public,所有成员函数都为virtual。如果你没学过C++的话,可以忽略这句话)
5.2 类定义语法
最简单的类定义为以下结构:
1 | class ClassName: |
与函数定义 (def 语句) 一样,类定义必须先执行才能生效。\
在类里可以定义成员变量(属性)和成员函数(方法),不过类里的成员函数需要一个特殊的形参。
类对象支持两种操作:属性引用和实例化。
属性引用是指通过类名加一个点号,引出类的属性:
1 | class MyClass: |
定义之后你去执行 MyClass.i 就会获得12345这个数据。
执行 MyClass.f() 就会获得字符串。
5.3 类的实例化
类的实例化使用函数表示法。可以把类对象视为是返回该类的一个新实例的不带参数的函数。 举例来说(假设使用上述的类):
1 | class MyClass: |
创建类的新实例并将此对象分配给局部变量x。此时x就是MyClass类的一个对象。
此时我们创建的对象是一个空对象,仅仅只是把类的属性和方法“复制”了过来。许多时候我们需要让对象在初始化的时候具有某种状态,在类里有这么一个特殊的函数:
1 | def __init__(self): |
当一个类定义了 __init__() 方法时,在创建类的对象时会自动执行这个函数的代码,这个函数称之为构造函数。
注意,第一个self参数不可以省略。
当然,构造函数可以传递几个参数:
1 | class Person: |
将自动输出 Hello, Kotori!
5.4 方法的self参数
在上面的类定义中,你会发现所有的函数第一个形参都为self(除了@staticmethod)。
在Python中,self参数是实例方法的第一个参数,它代表类的实例本身。通过self,你可以访问实例的属性和其他方法。
形象的来说,self参数就是对象本身,不是类本身。
1 | class Person: |
在实例化a对象的时候,调用的初始化函数中的self就是a对象的引用,在实例化b对象的时候,调用的初始化函数中的self就是b对象的引用。
在a对象调用getName的时候,方法中的self参数就是a的引用,b对象调用getName的时候,方法中的self参数就是b的引用。
在Python中,调用对象的方法时,会自动传递对象的引用给self,但是在类里定义对象方法的时候,需要显示写出self参数,即对象方法的第一个参数始终为self。
5.5 类的变量和实例变量
一般来说,实例变量用于每个实例的唯一数据,而类变量用于类的所有实例共享的属性和方法:
1 | class Dog: |
简单来说,类的变量直接定义在类里面,如例子的kind变量,这样的变量可以被所有类的实例化访问到(也可以直接通过类名进行访问)。而通过实例方法,给self赋值的变量,属于实例变量,只能被这个实例本身所使用。
类的变量可以供所有实例共享,不建议使用这样的变量。(你可以用来存储常量)
5.6 静态方法
刚才说了,类的所有的方法第一个形参都为self(除了@staticmethod)。
被 @staticmethod 修饰的方法称之为静态方法,调用静态方法的时候不会给方法传递默认的self了,因此静态方法不能访问实例变量,因此很少用。
5.7 继承
使用类的继承,可以轻松的将其他类的属性和方法复用。结构如下:
1 | class 子类(父类): |
只是在先前的类定义中,用括号将父类括起来。
简单来说,子类直接拥有父类的属性和方法,并可以定义属于自己的属性和方法。
如果子类的成员与父类成员冲突,则子类成员会覆盖掉父类成员。
子类的构造函数内,需要调用父类的构造函数,使用如下结构:
1 | class Derived(Base): |
例如:
1 | class Parent: |
在这个例子中,Child类继承了Parent类的属性parent_attribute和方法parent_method,同时定义了自己的属性child_attribute和方法child_method。
总结
类是由变量与函数组成的具有一定意义的集合体。类是一个模板,在使用的时候需要实例化为一个对象。类的方法第一个参数需要始终为self,self参数就是对象本身,可以通过self.创建属于对象自己的变量。在调用对象的方法时需要使用点号引出。
一个类可以继承先前定义好的类,可以实现父类代码的复用。
在本基础教程中,没有涉及多态、抽象、以及多继承等复杂的类。
第五章 文件读写、错误与异常
5.1 文件读写
5.1.1 打开文件
open() 函数返回一个文件对象,最常使用的是两个位置参数和一个关键字参数:
1 | # 函数最常用的形参,其中encodeing为关键字参数 |
第一个实参是文件名字符串。第二个实参是包含描述文件使用方式字符的字符串。mode 的值包括 ‘r’ ,表示文件只能读取;’w’ 表示只能写入(现有同名文件会被覆盖);’a’ 表示打开文件并追加内容,任何写入的数据会自动添加到文件末尾。’r+’ 表示打开文件进行读写。